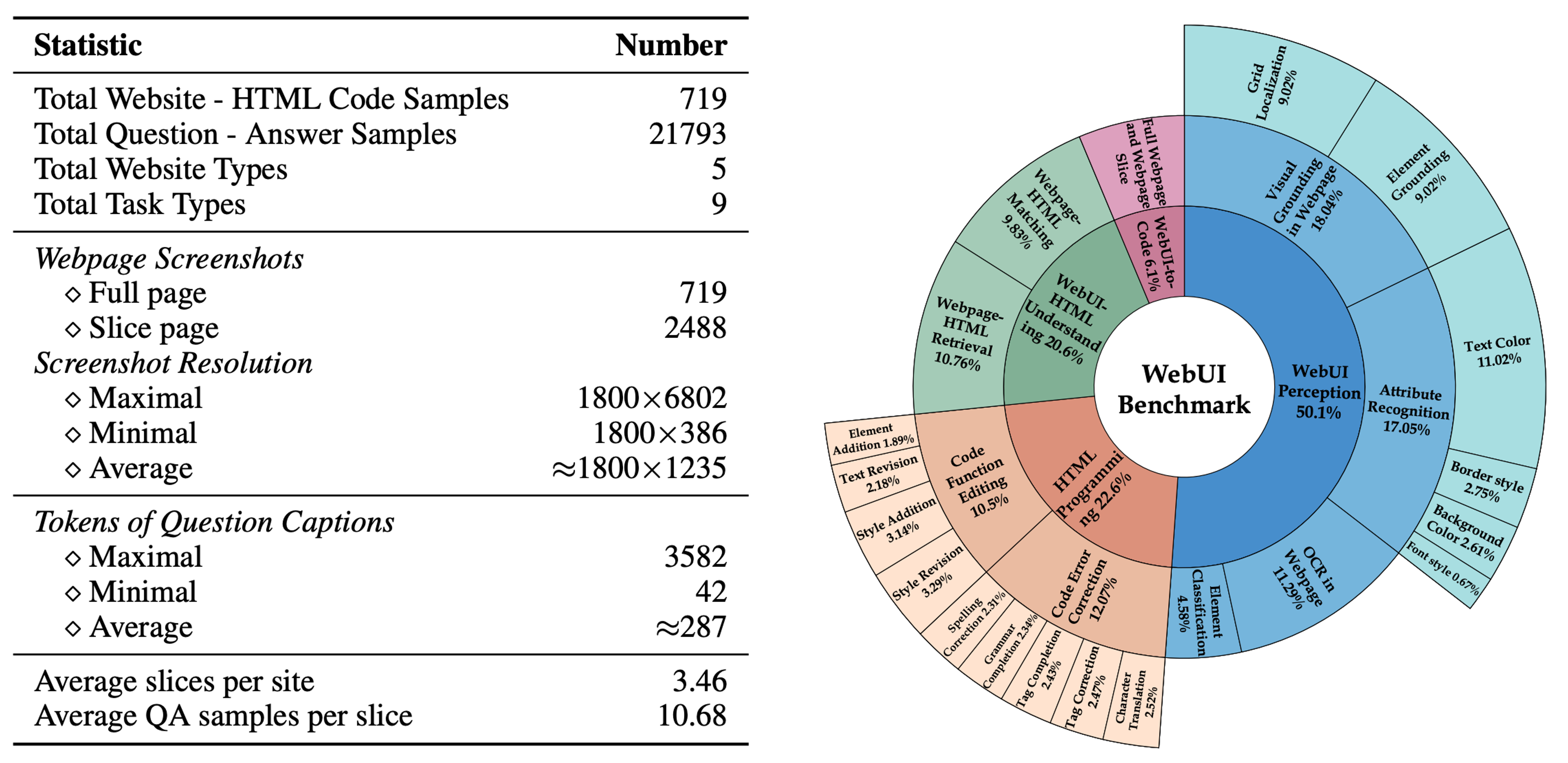
Evaluation taxonomy(left) and Task examples(right) of WebUIBench.
Abstract
The emergence of Large Language Models(LLMs) has rapidly reshaped the landscape of software engineering. AI code generation evolves from assisting developers to independently completing the entire development lifecycle (i.e., AI software engineer). With the rapid advancement of Generative AI technology, Multimodal Large Language Models(MLLMs) have the potential to act as AI software engineers capable of executing complex web application development.
Considering that the model requires a confluence of multidimensional sub-capabilities to address the challenges of various development phases, constructing a multi-view evaluation framework is crucial for accurately guiding the enhancement of development efficiency. However, existing benchmarks usually fail to provide an assessment of sub-capabilities and focus solely on webpage generation outcomes.
In this work, we draw inspiration from the principles of software engineering and further propose WebUIBench, a benchmark systematically designed to evaluate MLLMs in four key areas: WebUI Perception, HTML Programming, WebUI-HTML Understanding, and WebUI-to-Code. WebUIBench comprises 21K high-quality question-answer pairs derived from over 0.7K real-world websites. This paper has been accepted by ACL 2025 (findings).